Method
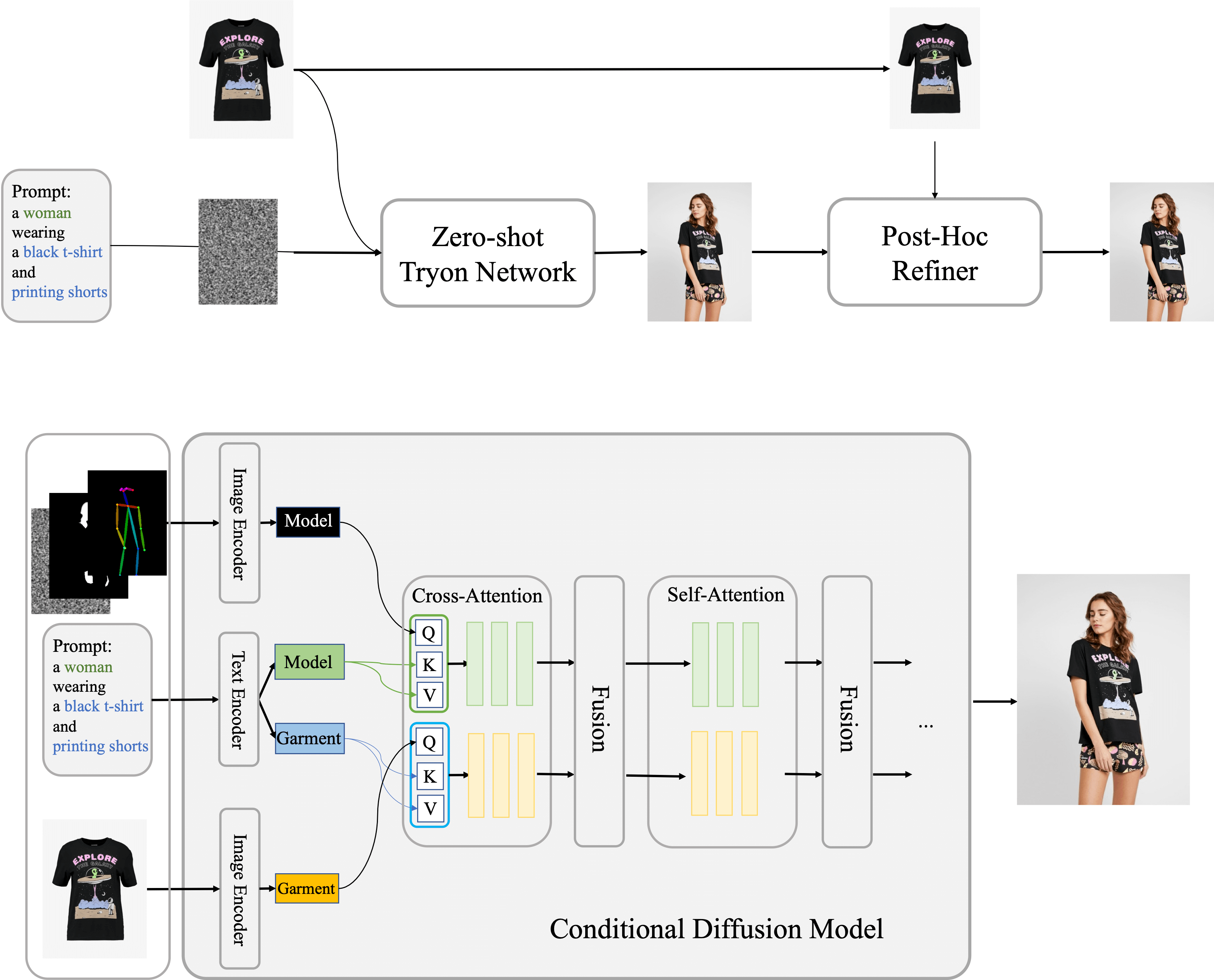
The conditional Diffusion Model central to our approach processes images of the model, garments, and accompanying text prompts, using garment images as the control factor. Internally, the network segregates into two streams for independent processing of model and garment data. These streams converge within a fusion network that facilitates the embedding of garment details onto the model's feature representation. On this foundation, we have established Outfit Anyone, comprising two key elements: the Zero-shot Try-on Network for initial try-on imagery, and the Post-hoc Refiner for detailed enhancement of clothing and skin texture in the output images.
Various Try-On Results
Real World
We showcase Outfit Anyone's capability for versatile outfit changes, including full ensembles and individual pieces, in realistic scenarios.
Individual Garment
Outfit
Bizarre Fashion
Here we showcase our model's ability to handle a wide range of eccentric and unique clothing styles, dress them onto the models, and even create corresponding outfit combinations when necessary.










Various Body Shapes
Our model demonstrates the ability to generalize to various body types, including those that are fit, curve and petite, thereby catering to the try-on demands of individuals from all walks of life.





Anime
we demonstrate the powerful generalization ability of our model, which can support the creation of new animation characters.


Refiner
Furthermore, We showcase the effects before and after using the Refiner, demonstrating its ability to significantly enhance the texture and realism of the clothing, while maintaining consistency in the apparel.








Outfit Anyone + Animate Anyone
We demonstrate the integration of Outfit Anyone with Animate Anyone, a state-of-the-art pose-to-video model, to achieve outfit changes and motion video generation for any character.