Method
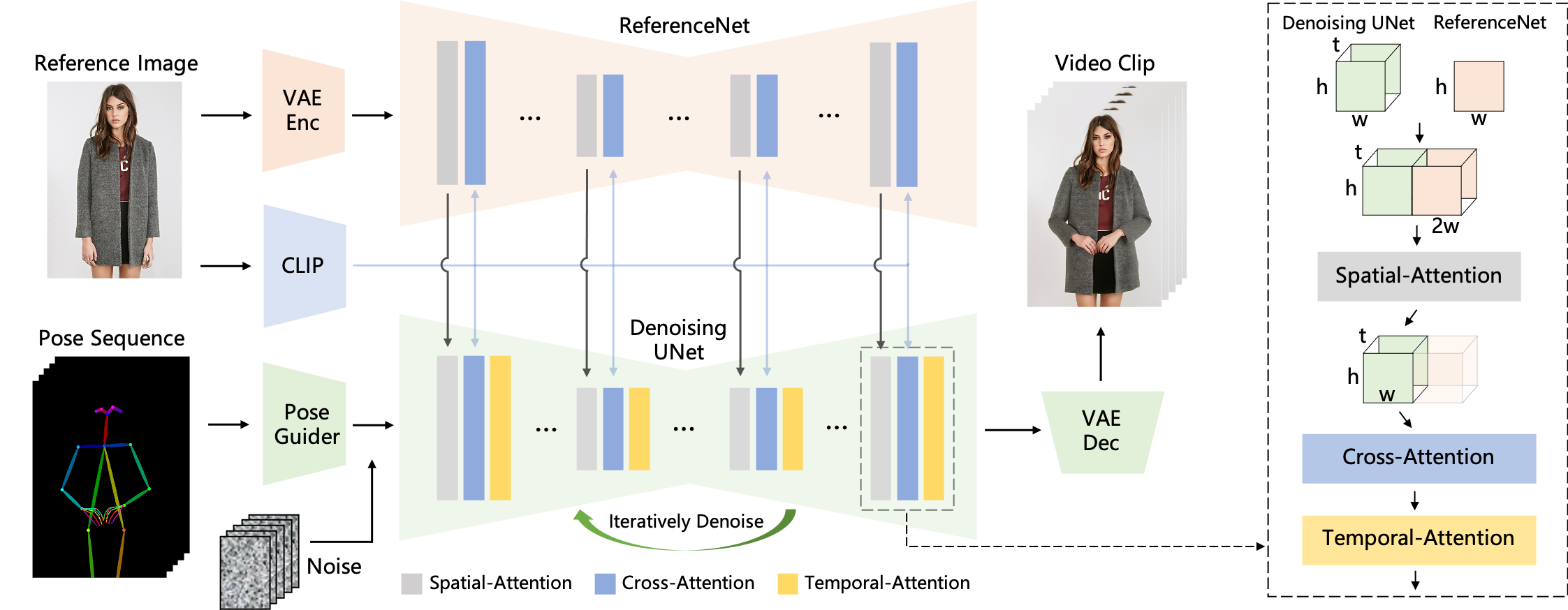
Character Animation aims to generating character videos from still images through driving signals. Currently, diffusion models have become the mainstream in visual generation research, owing to their robust generative capabilities. However, challenges persist in the realm of image-to-video, especially in character animation, where temporally maintaining consistency with detailed information from character remains a formidable problem. In this paper, we leverage the power of diffusion models and propose a novel framework tailored for character animation. To preserve consistency of intricate appearance features from reference image, we design ReferenceNet to merge detail features via spatial attention. To ensure controllability and continuity, we introduce an efficient pose guider to direct character's movements and employ an effective temporal modeling approach to ensure smooth inter-frame transitions between video frames. By expanding the training data, our approach can animate arbitrary characters, yielding superior results in character animation compared to other image-to-video methods. Furthermore, we evaluate our method on benchmarks for fashion video and human dance synthesis, achieving state-of-the-art results.
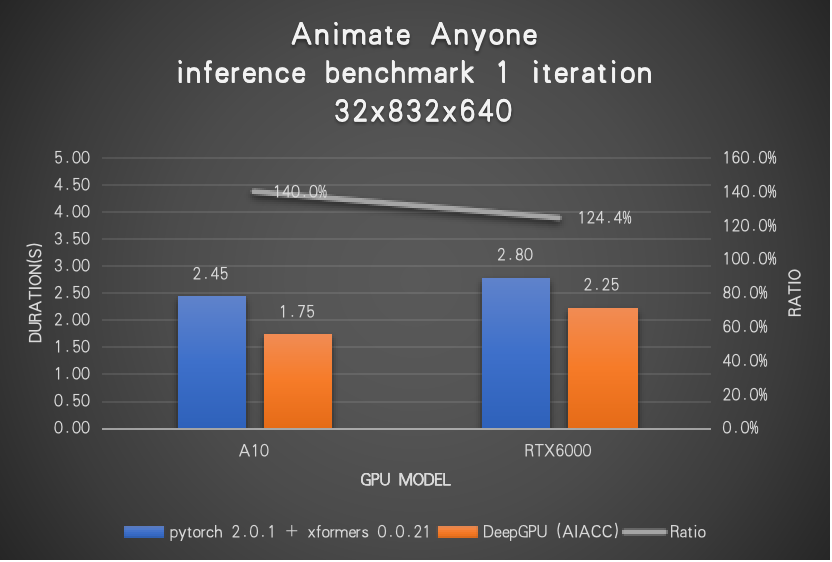
Animate Anyone video generation workloads are accelerated by DeepGPU (AIACC) of Alibaba Cloud with immense performance uplift compare to the original pytorch + xformers solution without hurting the quality of generated videos. This helps inference workloads reduce around 30% waiting time for end users as well as operating cost which makes a better user experience and cost-effective AI solution. The chart below shows some details of performance numbers on Animate Anyone inference that accelerated by DeepGPU. As observed from the chart, 32 frames 832x640 resolution video generation duration in 1 step reduces from 2.45s to 1.75s on A10 GPU when the inference is powered by DeepGPU acceleration which achieves 40% performance gain, while on RTX6000 GPU, the number reduces from 2.8s to 2.25s, nearly 25% advantages over pytorch.
@article{hu2023animateanyone,
title={Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation},
author={Li Hu and Xin Gao and Peng Zhang and Ke Sun and Bang Zhang and Liefeng Bo},
journal={arXiv preprint arXiv:2311.17117},
website={https://humanaigc.github.io/animate-anyone/},
year={2023}
}